
티스토리 뷰
내가 선택하는 내 영화 취향: 뭘고를지 몰라 다 준비해봤어
NAVER Engineering | 권은/김동국 - 내가 선택하는 내 영화 취향: 뭘고를지 몰라 다 준비해봤어
tv.naver.com
후기
- 내가 진행했던 프로젝트인 영화추천 서비스와 어떻게 다를지, 알고리즘은 어떻게 구성했는지 모델링은 어떻게 했는지 등 궁금한게 생겨서 보게 되었다.
- 나는 기본적인 장고와 파이썬을 기반으로 나름대로의 알고리즘을 짜고 ORM 을 조작해서 구조화했다.
- 네이버 영화취향은 보다 고도화된 알고리즘을 사용했고, 장르를 기반으로 한다.
- 아직은 어렵지만, 내가 프로젝트를 해보고 이 영상을 보니 이해되는 부분도 많고 일부는 구현해볼 수 있겠는데? 하는 생각도 든다. :) !!
알고리즘 구조
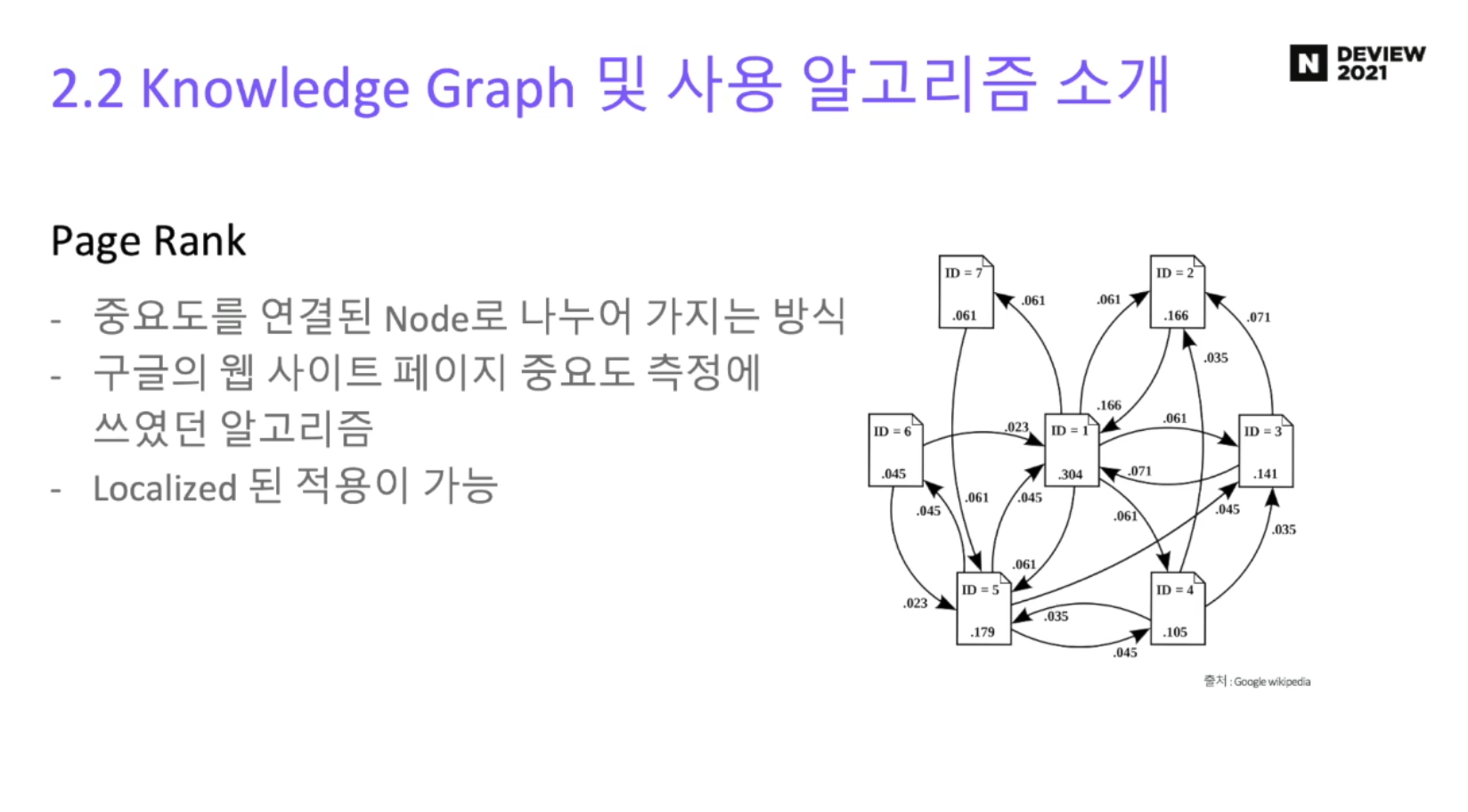
- 네이버 영화취향은 Knowledge Graph 를 사용하는데, 사회연결망 그래프라고 보면된다.

그 중 Page Rank Centrality 를 사용한다.
각 노드들이 릴래이션십을 기반으로 중요도를 공유하였을때 결과적으로 얼만큼의 영향력을 가지게 되는가?
데이터 클리닝
1. 메인장르와 서브장르 구분
적절한 결과를 위한 데이터 처리
-> 특정 메인 장르는 삭제한다. (메인장르 중 영화수가 너무 작은 것은 삭제) 여기선 아마도 미스터리이지 않을까?

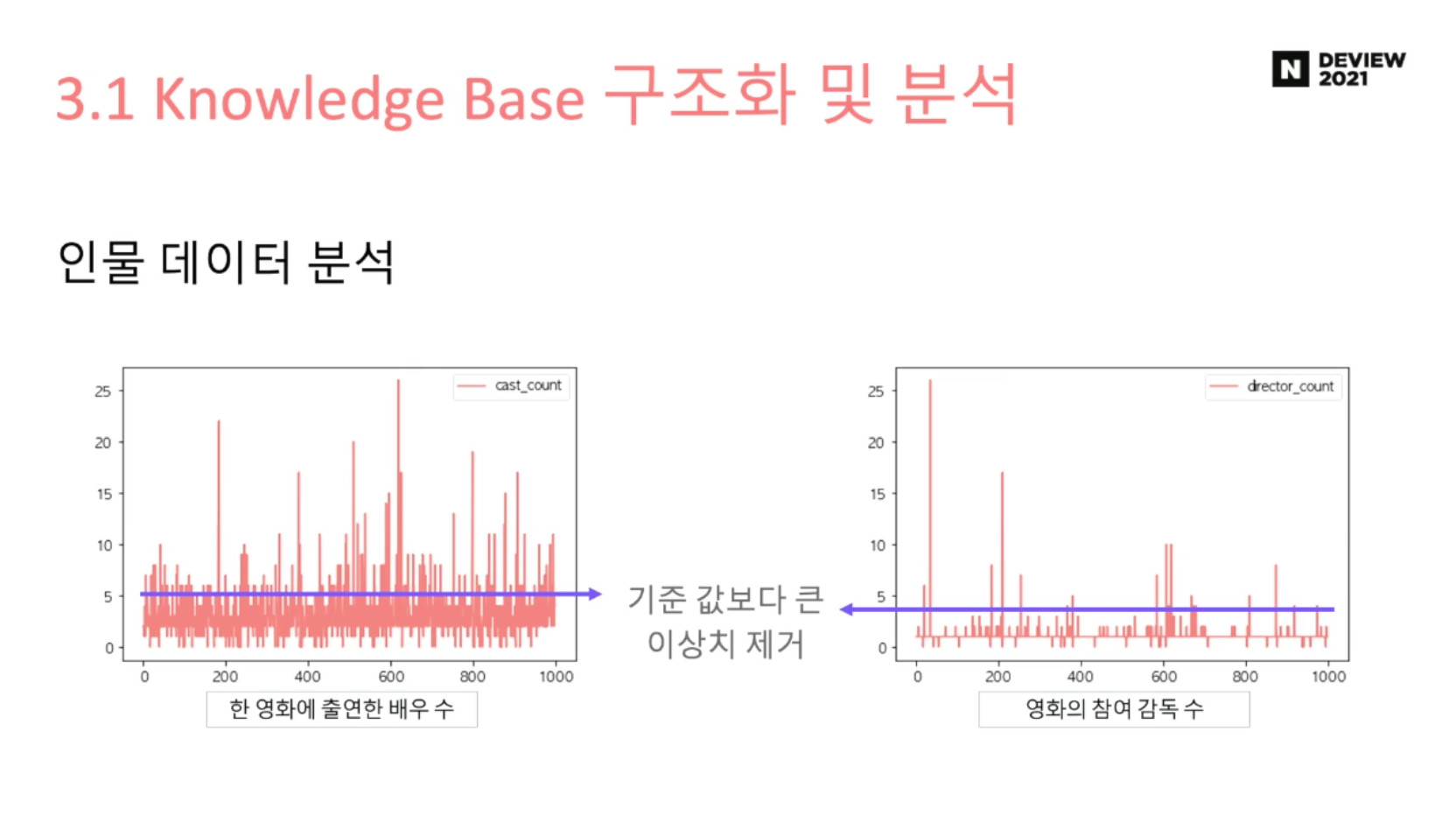
2. 인물 데이터 분석
너무 많은 노드와 연결되면 관계성 파악이 어려워진다.
-> 기준값을 정해서 해당 값 이하의 인물만 연결되도록 한다.

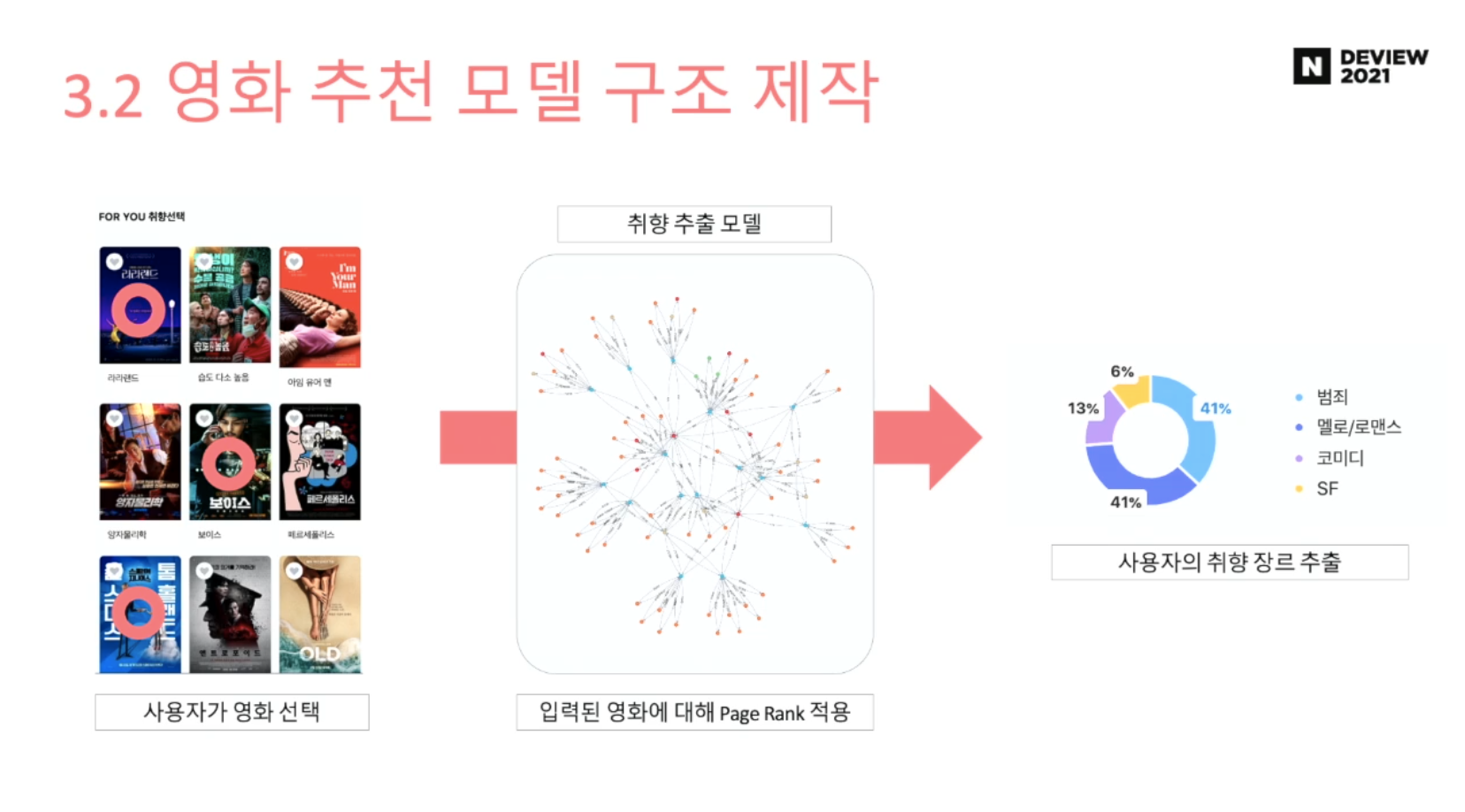
취향 장르 추출하면, 그 장르를 다시 추천영화 모델이 입력하여
취향 장르에 알맞는 영화를 추천한다.
v 취향장르 추출모델
v (장르기반) 추천영화 모델
이걸 연결할 때(?) 취향장르 가중치 비율이 조정되면 추천영화도 바뀌도록
페이지랭크 점수를 입력받는 취향 장르별로 기록한다.

추가적으로 관심도 반영
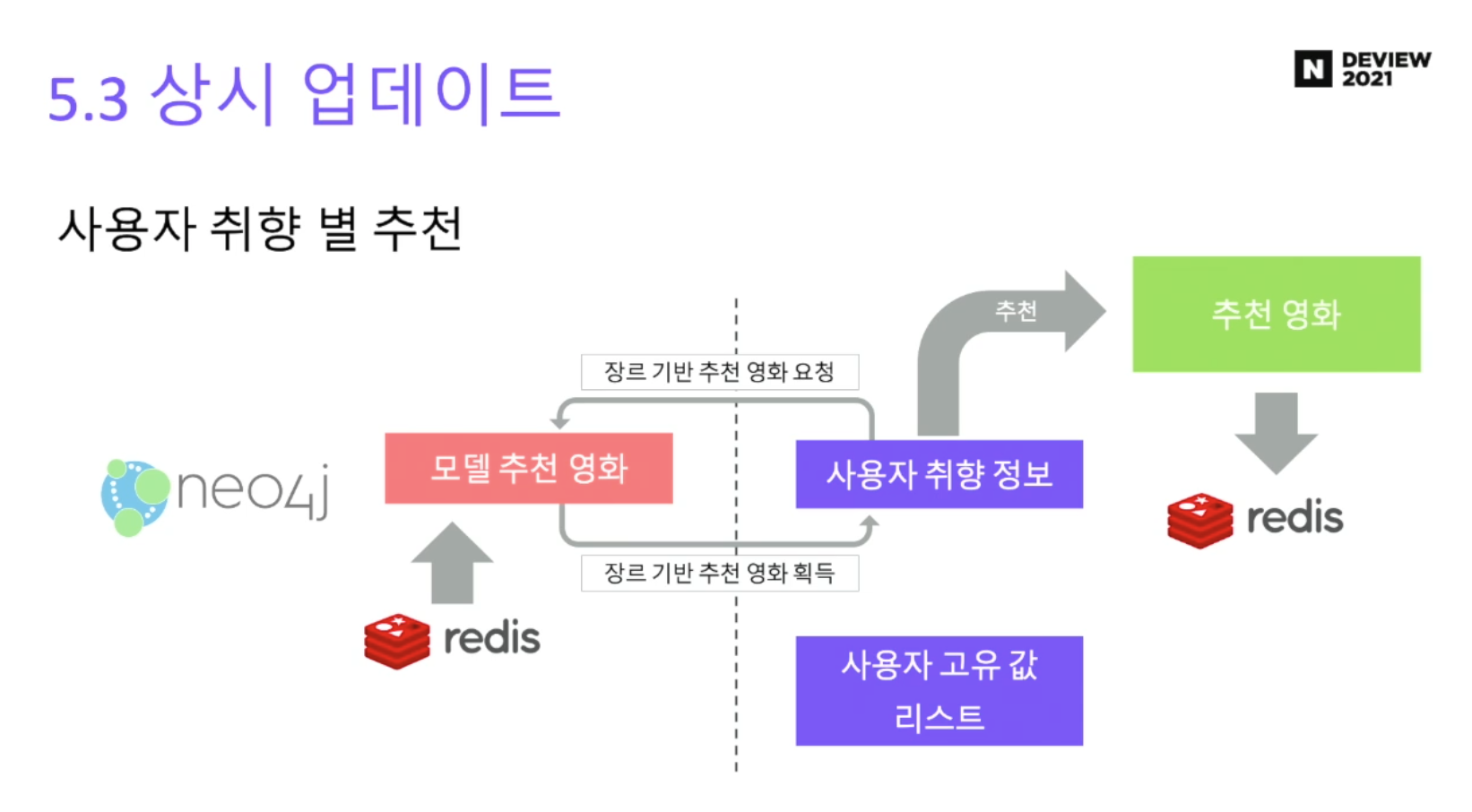
시스템 구조
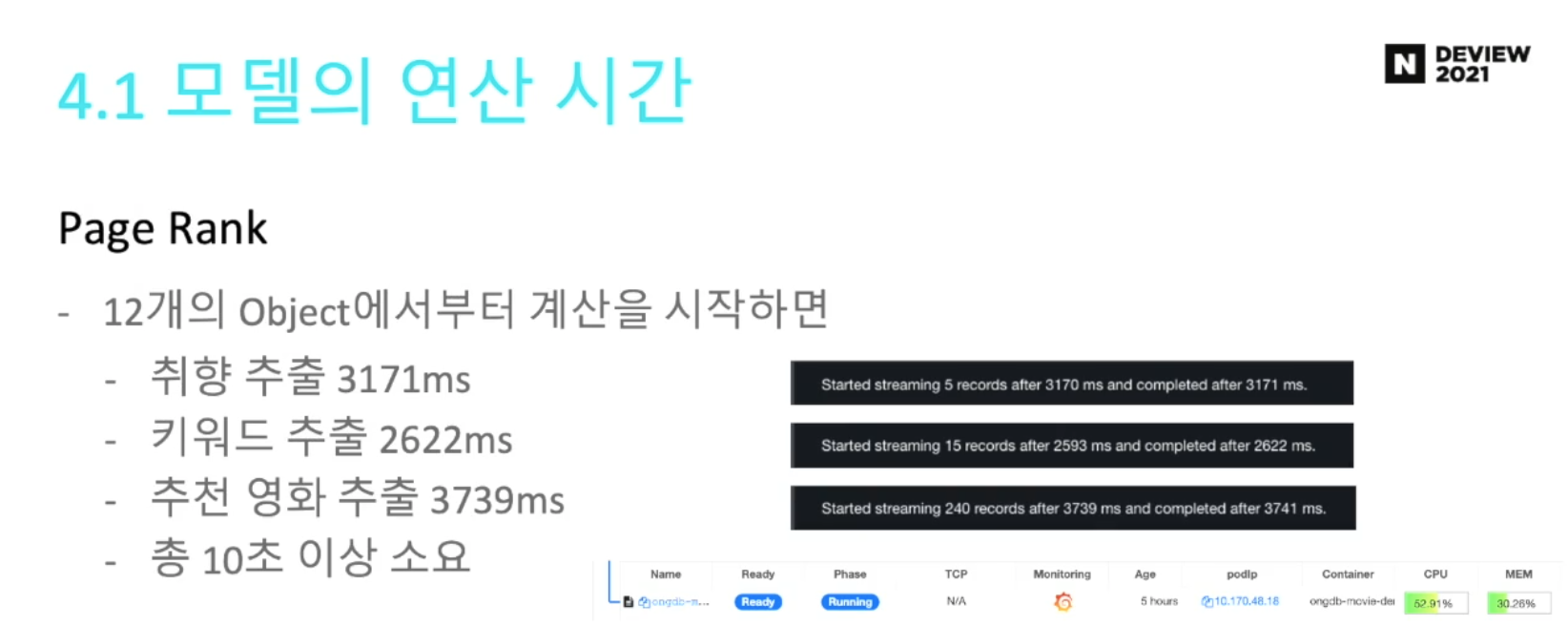
=> 이 연산에 시간이 너무 많이 걸려서....
미리 만들어놓음.
영화 장르는 한정적이니까, 공통계산과 계산점수를 미리 저장

모델연산은 neo4j, 그 결과를 redis에 key-value 데이터로 저장

1. 정기 업데이트를 진행 -> 영화리스트 선택 조합을 모두 생성해서 연산결과를 레디스에 저장
2. 취향 리스트를 레디스에 저장
3. 정보 기반으로 취향뽑고, 그걸로 다시 추천영화뽑음



1. 처음 선택시 -> 취향(장르) 저장
2. 취향별 추천 -> 추천영화 저장 (키값은 사용자의 고유키)
3. 조회시 앞의 연산 생략하고 추천영화만 보여줌


'Project' 카테고리의 다른 글
| 배포 structure(타프로젝트, 참고용) (1) | 2022.02.07 |
|---|---|
| 프로젝트 헬밀 MVP 최종발표 - LEAN UX 적용한 e-commerce webapp (0) | 2021.07.02 |
| 모바일 앱(App) 프로젝트 네번째 이야기. < 고치다 > (0) | 2020.10.22 |
| 모바일 앱(App) 프로젝트 세번째 이야기. < 배우다 > (0) | 2020.10.22 |
| 모바일 앱(App) 프로젝트 두번째 이야기. < 이야기하다 > (0) | 2020.10.22 |
- Total
- Today
- Yesterday
- intj여자
- SSAFY
- 폰트추천
- 맥과윈도우로깃허브
- 무료폰트추천
- 클린코드
- 개발자로드맵
- 상업용무료폰트
- 한글무료폰트추천
- 클린코더
- 폰트
- ssafy결과
- 디즈니얼굴
- 깃허브계정
- ssafy6기
- 개발자책추천
- ssafy합격후기
- 개발자
- 개발언어추천
- 개발자커리
- 개발자도서추천
- 개발언어순위
- 임대차3법
- ssafy후기
- 깃허브계정2개
- 코딩도서
- 브왈라
- 싸피
- 싸피6기
- 개발도서추천
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |